This story started with a compliment from upper management because IT was starting to do deployments at 05:00. In the morning. As traffic to our webshop in the early morning is less then during the day and evening this was seen as a good step.
The tweet
When you praise the team for deploying at 05:00 instead of 08:00 you incentivize the wrong solution for the deployment problems. #DevOps
— Melle Koning (@MelleKoning) January 14, 2014
User Stories
As company we want to be able to swiftly upgrade the software we serve to customers without any downtime.
As company we want to be able to deploy software during the day when all knowledge from colleagues is available to see if the deployment is OK.
As company we need to be able to deploy software in a risk-free manner by seeing that new versions of the software actually work as compared to an older version.
Current state of software deployments
Software is released at certain intervals (suppose, each week) at a very early time. We do this because at that time we have least traffic thus any downtime is less harmful than if the software would be deployed during high-traffic times.
Vision
Deploy new software any time without having any downtime and also compare the new version(s) of the software with the current live version.
Requirement of the software for this vision
New versions of software should not have ‘breaking changes’ from current versions. Whenever there is a breaking change, the two different versions cannot work simultaneously on different live machines.
Deployment without downtime explained
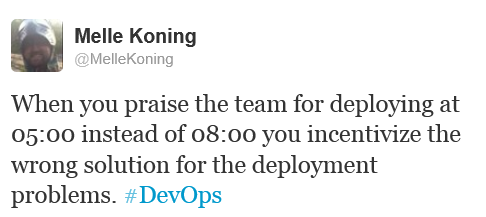
Looking at a live environment we see that the software is running behind a load balancer. Typical setup of software in a picture:
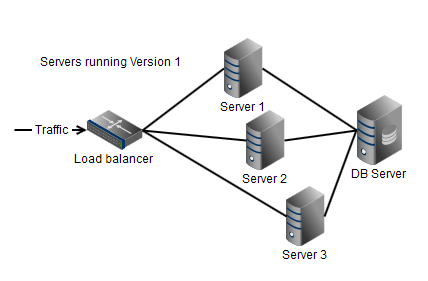
On live, each of the servers behind the load balancer is running the same version of the software.
Current way of deploying
Currently when we load a new version of the software to live, we always update ALL servers. The main reason we are still doing this is because a dependency of the software (like the database structure it is using) might also have an update, thus changed. In other words: old versions of the software can probably not work with the also upgraded dependencies.
Opportunity with backwards compatible software
However, now that we are deploying new software versions with valuable stories to live each week, the dependencies (like the database structure) are almost always backwards compatible with earlier versions of the software. Also, the way we are working now takes into account that the software is to be backwards compatible. We are often doing ‘cascade updates’ whereby the software can use ‘old structure’ as well as ‘the new structure’ of the database (or any other dependencies).
Proposal: No downtime deployment
Whenever there is no breaking dependency for new software, our update process to live should be done without any downtime.
Example of the steps that have to take place during an upgrade of software.
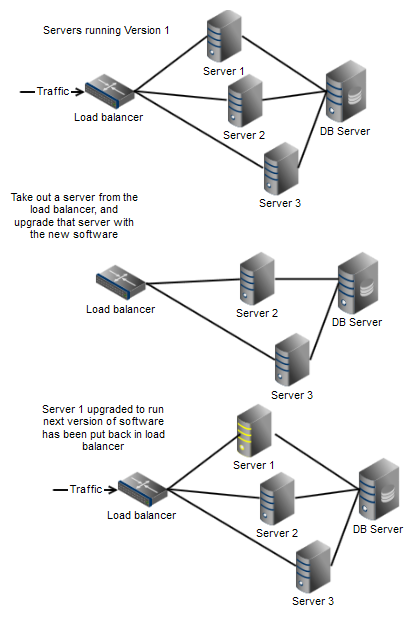
Now we have one server running the new software. We can first examine the output (logs and monitors) for this particular machine to see if the software is behaving correctly.
We can decide how long we want to examine.
- Inspect live logs
- Inspect monitors for this new machine
Now only if everything is proven to work based on our findings, we can then upgrade the other servers, one by one taking them out of the load balancer, upgrade the software and put back in the load balancer.
Fall-back scenario
If anything is failing for the upgraded server we should roll back that one server with the current version of the software. We should decide a rollback based on any findings in the log that are unique for this particular live machine. That is:
- Assure that the issue only occurs for the new software, and is not an already known existing cave-at of the software.
What are the benefits for this way of deploying software?
- Can upgrade software with no downtime for customers
- Can upgrade software any time of the day, thus when most knowledge for examining is available
When can we not use this approach?
If there are known breaking changes to the software and/or its dependencies then we are stuck with the existing ‘all-or-nothing’ approach of releases. This might be the case if keeping backwards-compatibility is more costly than building backwards-compatibility in.
What are known issues in backwards compatibility?
The most known issue for backwards compatibility is upgrading the database structure. Usually a removal of a column from a database table immediately suffers the existing running versions of the software.
Can that problem be circumvented?
Yes, this problem can usually be tackled by doing ‘cascade updates’ to the software. That is:
- Create a new software version (v2) that does not rely on the to-be-deleted data
- Release that software (v2) to live
- Only in a next release (v3) (the cascade-update release) include the database change script that removes the, now not used, database column
That concludes the proposal of no-downtime releases. Make use of your loadbalancers; release with ease.