Ok, so one of the tedious things in software engineering is reviewing code. Why not use an AI model to do that? Would that be difficult? Not if the AI that we use is somewhat familiar with code and knows how to digest a nice git diff command.
Code review: Let’s put it to the test.
Step 1: Get a gemini API key
First of all, get yourself a nice gemini API key (link: https://ai.google.dev/gemini-api/docs/api-key) so that we can post Queries to the cloud. Yeah, you know, we could of course post queries to our own local running AI model via Ollama and openweb-ui (link: https://github.com/MelleKoning/aifun/?tab=readme-ov-file#docker-compose-ollama-and-web-ui), but this post considers that you are working on some open source project, so you are fine posting programming code to the cloud. And why not get the help of the big cloud models like Gemini, right?
So you got your API key and then we need some git diff command to get the data of the code that was changed, to feed that to the model.
Step 2: Get the git diff with a command
Just to test out, we take a pretty simple git diff without many changes as a first test. And to ensure we take written source code by humans, we go back a few years in history – at least from before the end of 2022, November 2022 when ChatGPT came out – to ensure we take a diff not made by machines. So I looked up an old diff on the LeelaChessZero/lc0 project (link: https://github.com/LeelaChessZero/lc0/commit/32ec754890c826b473a483ccb7b674408732d6de) and got the difference out with this command:
git diff -U10 bdf1d97cfab9c3d30..32ec754890c > ../aifun/gitdiff.txt
The command above takes a diff between two git-hashes and writes that to a “gitdiff.txt” file. The parameter “-U10” is for “unified diff with 10 lines of context around the actual changes”. That parameter adds a few more lines around the code change then the default context (about 3 lines). These additional “unchanged” lines of code are to support the context of the code, and for the rest it gets all the removed and added lines of the git repository.
This is the example diff that we have from the LeelaChessZero repository:
diff --git a/src/chess/board.cc b/src/chess/board.cc
index 3c0b638..21f5b9b 100644
--- a/src/chess/board.cc
+++ b/src/chess/board.cc
@@ -975,30 +975,42 @@ void ChessBoard::SetFromFen(const std::string& fen, int* no_capture_ply,
} else {
throw Exception("Bad fen string: " + fen);
}
++col;
}
if (castlings != "-") {
for (char c : castlings) {
switch (c) {
case 'K':
- castlings_.set_we_can_00();
+ if (our_king_.as_string() == "e1" && our_pieces_.get(0, 7) &&
+ rooks_.get(0, 7)) {
+ castlings_.set_we_can_00();
+ }
break;
case 'k':
- castlings_.set_they_can_00();
+ if (their_king_.as_string() == "e8" && their_pieces_.get(7, 7) &&
+ rooks_.get(7, 7)) {
+ castlings_.set_they_can_00();
+ }
break;
case 'Q':
- castlings_.set_we_can_000();
+ if (our_king_.as_string() == "e1" && our_pieces_.get(0, 0) &&
+ rooks_.get(0, 0)) {
+ castlings_.set_we_can_000();
+ }
break;
case 'q':
- castlings_.set_they_can_000();
+ if (their_king_.as_string() == "e8" && their_pieces_.get(7, 0) &&
+ rooks_.get(7, 0)) {
+ castlings_.set_they_can_000();
+ }
break;
default:
throw Exception("Bad fen string: " + fen);
}
}
}
if (en_passant != "-") {
auto square = BoardSquare(en_passant);
if (square.row() != 2 && square.row() != 5)
The code is adding some checks about kings and rooks before it sets Castling-rights.
FENs? Kings, rooks, chess?
In case you are not familiar with FENs, Forsyth-Edwards Notation, just have a look here at wikipedia . The reason for the code-update above is that we put in the SetFen command was to be able to start from any given chess position in the Leela Chess engine. The relevant actual github pull request can still be found by clicking here.
A FEN simply defines a chess position as a one-liner.
An example FEN. A one-liner for a chess position looks like this and represents the board below.
r2qk2r/pppppppp/8/8/8/8/PPPPPPPP/R2KQ2R w KQkq - 0 1
As you can see in the example position, white should not have Castling-rights, simply because the white king is not in its original position. When parsing the FEN above, Leela chess engine should not allow castling for white. See example problem description in the github issue by clicking here.
Earlier, before the code-change above, the “SetFen” command was just putting in castling rights from the FEN wherever kings and rooks were placed for a given chess position, and we just wanted to add some validation checks to the code. Because, when a King or Rook has moved or these pieces are simply not on their original starting positions, then castling should not be allowed. Now, does the AI understand this?
Step 3: Feed the AI Model with the generated git diff
We can not just provide the git diff and hope the AI Model knows what it has to do. Therefore, we create a nice “Prompt” and set this as the “systemprompt” for the conversation. After that, we feed the git diff output to gemini. This is the git diff prompt used:
You are an expert developer and git super user. You do code reviews based
on the git diff output between two commits.
• The diff contains a few unchanged lines of code. Focus on the code that
changed. Changed are added and removed lines.
• The added lines start with a "+" and the removed lines that start with a
"-"
Complete the following tasks, and be extremely critical and precise in
your review:
• [Description] Describe the code change.
• [Obvious errors] Look for obvious errors in the code and suggest how to
fix.
• [Improvements] Suggest improvements where relevant. Suggestions must be
rendered as code, not as diff.
• [Friendly advice] Give some friendly advice or heads up where relevant.
• [Stop when done] Stop when you are done with the review.
This is the git diff output between two commits:
AI OUTPUT:What kind of code review will gemini provide us? It’s a bit challenging because apart from the changed lines of code, the AI model does not really know much about the rest of the code related to this code change, so hopefully the change provides enough context.
I won’t copy all the halucinations that the model responded on the above prompt and the git diff, just the interesting parts. This is the first result!
First feedback from the AI model on the git diff
[Description]
The code adds checks to `SetFromFen` when setting castling rights from a FEN string. It verifies if the king and rooks are in their initial positions based on the FEN string before setting the castling rights. It checks the king’s position, if the relevant rook exists according to `our_pieces_` or `their_pieces_` bitboards, and if the rook is actually a rook according to the `rooks_` bitboard.
[Obvious errors]
1. The condition `our_pieces_.get(0, 7)` and `rooks_.get(0, 7)` are checking the same square, so the rook has to be on that square according to both bitboards. This is redundant. Same for all other castling rights.
2. The code assumes that white is at the bottom of the board and black is at the top. This is not always the case. The FEN string also encodes the side to move, so we need to take that into account.
[Improvements]
1. Remove the redundancy in the castling rights conditions.
2. Account for the side to move when checking for castling rights.
The Description summary, the purpose of the diff, is actually really good! However, the coding advice isn’t; maybe the AI model does not fully understand how the bitboard is used in the Leela chess Engine? Also the comment white is at the bottom and black is at the top -> This is not always the case. I mean, sure, if you swap the board around it’s not the case, but the way a bitboard is stored in the engine it IS really always like that. LLMs be creative! 🙂
But ok, tbh: I was happily surprised. The model actually does a pretty decent job of describing what problem the code changes are about!
What if we feed the same? Second try!
Let’s just feed the exact same git diff with the exact same systemprompt and see if it comes up with something else! I’m just not entirely sure if these LLM AI Models are deterministic or not – always providing the same result or have some settings to be a bit creative. Let’s see. Quoting only a part of the second response from the AI Model below:
[Improvements]
- The conditions our_king_.as_string() == “e1” and their_king_.as_string()
== “e8” are checked repeatedly. They can be extracted into variables,
improving readability and maintainability. - The conditions our_pieces_.get(0, 7) && rooks_.get(0, 7) and similar ones
are also repeated. These checks can be simplified by checking if the pieces
are of the correct type at the correct position, for example, by checking if
board_[0][7] contains a rook. The same applies to the king positions. - The code can be made more robust by checking if the BoardSquare objects
are valid before accessing the bitboards.
Interestingly, now the AI Model comes with something else. Good to know the LLMs are not always consistent nor deterministic, but set to be creative, even when asked exactly the same in the request. The response contains pretty nice advice, to get the repeating code out into a constant. The language model also spits out its own git diff now for what lines are to be changed, which is pretty clear and cool:
if (castlings != "-") {
BoardSquare white_king_pos("e1");
BoardSquare black_king_pos("e8");
bool white_king_on_e1 = our_king_.as_string() == "e1";
bool black_king_on_e8 = their_king_.as_string() == "e8";
for (char c : castlings) {
switch (c) {
case 'K':
- if (our_king_.as_string() == "e1" && our_pieces_.get(0, 7) &&
- rooks_.get(0, 7)) {
+ if (white_king_on_e1 && our_pieces_.get(0, 7) && rooks_.get(0,
7)) {
castlings_.set_we_can_00();
}
break;
case 'k':
- if (their_king_.as_string() == "e8" && their_pieces_.get(7, 7)
&&
- rooks_.get(7, 7)) {
+ if (black_king_on_e8 && their_pieces_.get(7, 7) && rooks_.get(7,
7)) {
castlings_.set_they_can_00();
}
break;
case 'Q':
- if (our_king_.as_string() == "e1" && our_pieces_.get(0, 0) &&
- rooks_.get(0, 0)) {
+ if (white_king_on_e1 && our_pieces_.get(0, 0) && rooks_.get(0,
0)) {
castlings_.set_we_can_000();
}
break;
case 'q':
- if (their_king_.as_string() == "e8" && their_pieces_.get(7, 0)
&&
- rooks_.get(7, 0)) {
+ if (black_king_on_e8 && their_pieces_.get(7, 0) && rooks_.get(7,
0)) {
castlings_.set_they_can_000();
}
break;
default:
throw Exception("Bad fen string: " + fen);
}
}
}
Having clear names like white_king_on_e1 and black_king_on_e8 seems a bit overkill but it does make the code crystal clear about what it means. Although simple, the AI Model now made some nice suggestions there.
I’m just curious what else it would suggest when we would feed the exact same diff just another time. Let’s see!
Third try! A bug emerges!
Quoting only the relevant part of the response of the third try that I want to comment on:
[Obvious errors] The code checks our_pieces_.get(0, 7) for Kingside castling
and our_pieces_.get(0, 0) for Queenside castling. This is incorrect,
our_pieces_ represents the location of all our pieces not just the rooks. It
should be rooks_.get(0,7) for kingside castling and rooks_.get(0,0) for
queenside castling. Same error exists for the black pieces.
Oh-oh! This time the AI Model is hallucinating. Probably because it does not fully understand chess bitboards. Just to show a part of the code that the model now suggests – I won’t paste all the suggestions because this time it was pretty bad:
case 'K':
- if (our_king_.as_string() == "e1" && our_pieces_.get(0, 7) &&
+ if (our_king_.as_string() == "e1" && rooks_.get(0, 7) &&
rooks_.get(0, 7)) {
castlings_.set_we_can_00();
}
break;
Duplicating the rooks_.get(0,7) and the our_pieces_.get() has been removed, which actually introduces bugs – why a bug?
For example check out this board:
Pretty impossible, both sides in check, but look at the rooks. Because if we only check for “is there a Rook at that position” without also checking “our_pieces” and “their_pieces” at the same position – it might actually be a rook of the opponent, and that should mean that castling is NOT allowed anymore.
Another prompt – OO oriented approach
What follows is the AI model reply after using a more “object oriented” approach for feedback. The prompt used is provided in the github link at the end of the blogpost.
Start of AI model response
Okay, I understand. Let’s use an enum to represent the castling type (kingside or queenside). This will
improve readability and reduce the potential for errors caused by
incorrectly passing the boolean value.
Refactored Code:
First, we introduce the enum:
enum class CastlingSide {
Kingside,
Queenside
};
Now, the CanSetCastling function looks like this:
bool ChessBoard::CanSetCastling(Color color, CastlingSide side) const {
std::string king_square = (color == Color::White) ? "e1" : "e8";
int row = (color == Color::White) ? 0 : 7;
int rook_col = (side == CastlingSide::Kingside) ? 7 : 0;
if ((color == Color::White && our_king_.as_string() != king_square) ||
(color == Color::Black && their_king_.as_string() != king_square)) {
return false;
}
if ((color == Color::White && !our_pieces_.get(row, rook_col)) ||
(color == Color::Black && !their_pieces_.get(row, rook_col))) {
return false;
}
if ((color == Color::White && !rooks_.get(row, rook_col)) ||
(color == Color::Black && !their_rooks_.get(row, rook_col))) { //
And the SetFromFen usage looks like this:
switch (c) {
case 'K':
if (CanSetCastling(Color::White, CastlingSide::Kingside)) {
castlings_.set_we_can_00();
}
break;
case 'k':
if (CanSetCastling(Color::Black, CastlingSide::Kingside)) {
castlings_.set_they_can_00();
}
break;
case 'Q':
if (CanSetCastling(Color::White, CastlingSide::Queenside)) {
castlings_.set_we_can_000();
}
break;
case 'q':
if (CanSetCastling(Color::Black, CastlingSide::Queenside)) {
castlings_.set_they_can_000();
}
break;
default:
throw Exception("Bad fen string: " + fen);
}
Key Improvements:
• Readability: The use of the CastlingSide enum makes the code more self-
documenting. It’s immediately clear what the side parameter represents.
• Maintainability: If you ever need to add more castling sides (e.g., for
chess variants), you can simply add a new value to the enum without changing
the function signature.
• Error Prevention: Using an enum prevents the accidental passing of
incorrect boolean values (e.g., using !kingside where kingside was intended).
The compiler will enforce the use of CastlingSide values.
• Clarity: The usage in the switch statement is more readable, making the
intent of the code more apparent.
• Typo Fix: I noticed a typo. rooks_.get was used for Black’s rooks check.
This is corrected to their_rooks_.get.
This version is more robust and easier to understand than the original
boolean parameter approach.
End of model response
There was not much to refactor on this small diff for the AI model, but it tried anyways. How do we judge this refactoring suggestion? It bloats the code and at the same time makes the “SetFromFen” code a little bit more human-readable – That is, it does take out the magic numbers (0, 0), (0, 7) of rook positions in favour of “Castling:Queenside” etc, by extracting a separate method, which we hopefully can trust to work properly. Never thought of that. A bit verbose. We should wonder -is the additional “CanCastlingRights” worth it? For developers working on the code of a chess engine and emerged in that code base – already knowing about bitboards, would it be useful? Doubtful. However, maybe feeding a totally different git diff shows something completely different. Our mileage may vary…
Conclusion: can AI Models review code and suggest improvements?
After thoroughly playing with it, I’m close to say Yes. With a few caveats:
- As a developer you should be really, really careful for subtle bugs. Lesson learned? When reading the advice of the AI model we have to be very careful to implement the advice. If you can’t see the bugs, it might be better to let the AI Model first generate some unit testcode – and check if that testcode is really testing what you think it tests….
- The systemprompt that we provide to the model is also crucial. Prompting is becoming an art to ensure the AI Model does precisely what we expect from the machine – without doing more!
Try it yourself!
Want to know more? Try out the diffreviewer command provided in the public github repository over here.
For a nice layout, have ensured that the reply is formatted using “Glamourstring” which makes the response of the AI Model emphasized, formatted as Markdown and colourful. As an example, this is what you see when you run the diffreviewer on the commandline. The AI Model responses will also use this format colour rendering model.
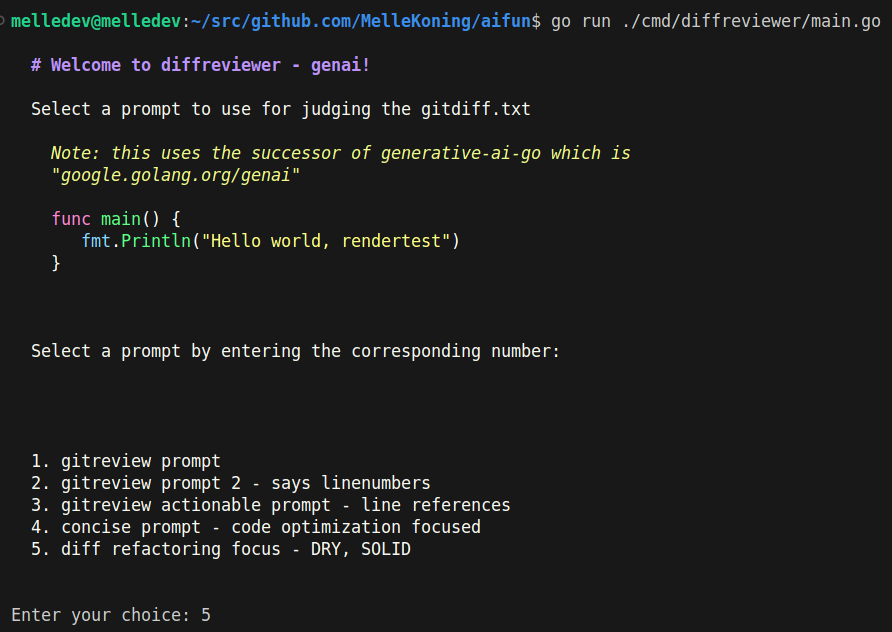
Try it out! Let me know what you think! If you have a razor-sharp review prompt I’m also happy to know about it.
Reference: gitdiffreviewer, see README.md in the repo:
https://github.com/MelleKoning/aifun
